Interview with Prof Luis Martí-Bonmatí. Director of the Clinical Area of Medical Imaging Department at La Fe Polytechnic and University Hospital and Head of Radiology Department at QuironSalud Hospital in Valencia
In ProCAncer-I you advertise that the platform that will be built will host the largest collection of PCa multi-parametric, anonymized image data worldwide. Why is this so innovational and maybe difficult?
The collection of medical images in standardized and interoperable repositories is a critical step when dealing with observational studies and predictive modelling. A large number of high quality and properly annotated images is necessary to build robust and generalizable AI-based solutions. These images, MR in the case of PCa, must have been acquired in different hospitals, vendors and acquisition protocols to be able to train and validate the computational algorithms and models to allow early diagnosis, adequate phenotyping, and individually-tailored treatments in a real-world clinical environment. In order to implement these solutions in clinical practice, images in these repositories must be harmonized to be vendor-protocol agnostic and comply with a high image resolution quality to avoid potential biases, as well as to incorporate trustworthy automated annotations based on well-established medical imaging standards. This is a huge and complex challenge that is meant to revolutionize the clinical workflow and lay the foundations of the precision and personalized medicine of the future.
What strategies have you adopted to improve the ProCAncer-I data extraction process at your center regarding clinical data?
Our academic hospital has two Data Warehouses (Figure), one for healthcare daily management (primary use) and the other for research on data studies (secondary use). In this way, a segmentation in the accesses and an adequate use of data according to specific needs is achieved. The primary data lake is rebuilt daily via an Extract-Transform-Load (ETL) process. Next, the research data lake is generated on two steps. After an exact copy of the primary Data Warehouse is acquired, the execution of a pseudonymization algorithm allows the generation of this repository for secondary use. All the information is then standardized with the OMOP Common Data Model (CDM), which allows to extract the needed clinical data in an efficient way. As all the data in the Data Warehouse is pseudonymized, data can be updated and curated for completeness if any information is missing in the extracted OMOP database. Even more, the process is iterative and missing information allows to improve the ETL script performed to create the OMOP database. In this way, a final robust data warehouse with high quality data is obtained for patients with prostate cancer in the so many clinical scenarios within the complex ProCAncer-I project.
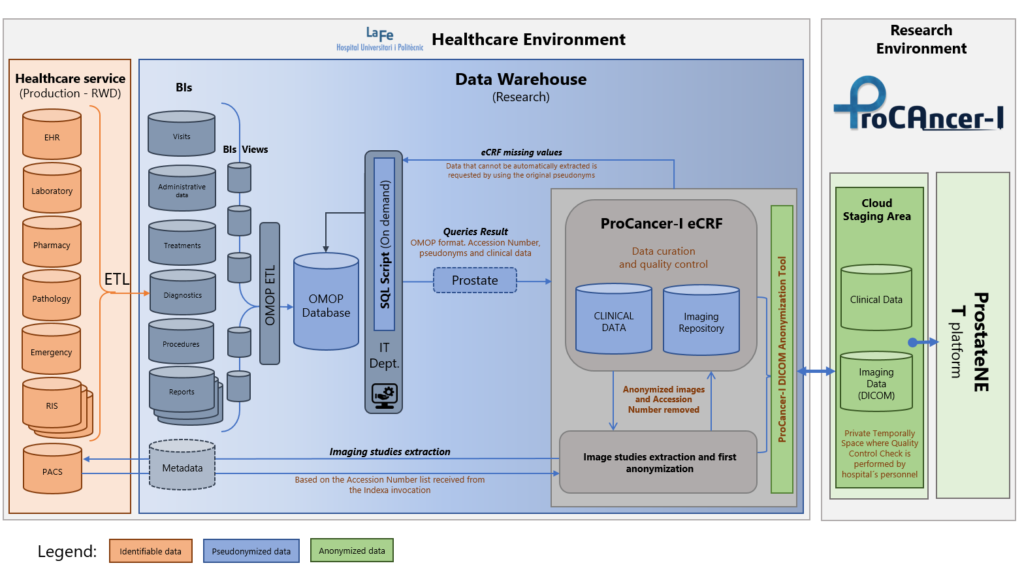
And regarding imaging data? What strategies are implemented in your hospital?
Images and clinical data are related in the Data Warehouse via the DICOM metadata and pseudonymized accession number. Due to the large amount of storage required, images are extracted only on demand as needed within the project. Images are anonymized and stored into our local image repository within the Biomedical Imaging Research Group (GIBI230) facility. The same anonymization code will be used for the clinical, molecular, pathology and imaging data of a patient.
What will be your contribution in the ProCAncer-I in terms of data?
Our hospital is the largest center of the Valencian Community and one of the largest in Spain. The hospital has more than 200 new patients with prostate cancer every year. We will provide at least 900 different cases to the ProCAncer-I platform. Up to now, once the automatic ETL extraction process has been set up and implemented at the Data Warehouse, we have initially identified around 500 cases. At first curation, at least 250 patients have all the necessary clinical variables. These are ready to be uploaded to the last version of the eCRF ProCAncer-I platform. Further steps will be focused on the recruitment of more patients fulfilling all the Use Cases scenarios within the ProCAncer-I project.
